AI算法为什么会存在性别歧视?谷歌做出了解释
一直以来,通过研究表明,人类研发的机器也能学习到人类看待这个世界的视角,无论其是否有意。对于阅读文本的人工智能来说,它可能会将“医生”一词与男性优先关联,而非女性,或者图像识别算法也会更大概率的将黑人错误分类为大猩猩。
2015年,Google Photos应用误把两名黑人标注为“大猩猩”,当时这一错误意味着谷歌的机器学习还处于“路漫漫其修远兮”的状态。随后,谷歌立即对此道歉,并表示将调整算法,以修复该问题。近日,作为该项错误的责任方,谷歌正在试图让大众了解AI是如何在不经意间永久学习到创造它们的人所持有的偏见。一方面,这是谷歌对外PR(公共关系)的好方式,其次,AI程序员也可以用一种简单的方法来概述自己的偏见算法。
在该视频中,谷歌概述了三种偏见:
互动偏差:用户可以通过我们和其交互的方式来偏移算法。例如,谷歌把一些参与者召集其起来,并让他们每人画一只鞋,但多半用户会选择画一只男鞋,所以以这些数据为基础的系统可能并不会知道高跟鞋也是鞋子。
潜在偏差:该算法会将想法和性别、种族、收入等不正确地进行关联。例如,当用户在Google Search搜索“医生”时,出现的大多为白人男性。
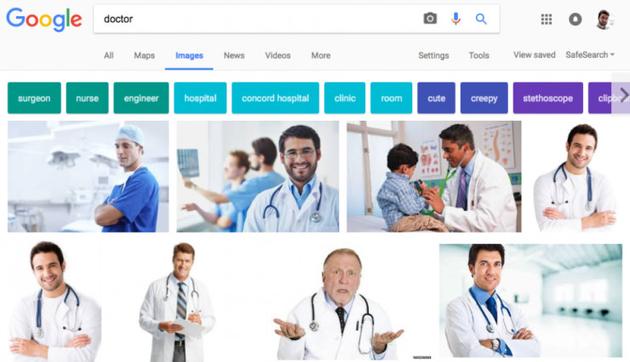
雷锋网了解到,此前Quarts发布了一则相关新闻,该报道称,经普林斯顿大学最新研究成果表明,这些偏见,如将医生与男性相关联,而将护士与女性关联,都来自算法被教授的语言的影响。正如一些数据科学家所说:没有好的数据,算法也做不出好的决策。
选择偏差:据了解,用于训练算法的数据量已经大大超过全球人口的数量,以便对算法实行更好的操作和理解。所以如果训练图像识别的数据仅针对白人而进行,那么得到的数据也只能来自AI的认定。
 图片来源:Qaurtz
图片来源:Qaurtz去年6月, “青年实验室”(英伟达、微软等科技巨擘均是该实验室的合作伙伴和支持者)举办了一次Beauty.ai的网络选美大赛。该比赛通过人工智能分析,征集了60万条记录。该算法参考了皱纹、脸部比例、皮肤疙瘩和瑕疵的数量、种族和预测的年龄等等因素。最后结果表明,种族这一因素比预期发挥了更大的作用:在44名获奖者当中,其中有36人为白人。
事实上,关于算法中含有性别、种族偏见的研究和报道,早已有之。而据雷锋网此前报道,要消除这些偏见,并不容易。正如微软纽约研究院的高级研究员Hanna Wallach所说:
“只要机器学习的程序是通过社会中已经存在的数据进行训练的,那么只要这个社会还存在偏见,机器学习也就会重现这些偏见。”

发表评论